Sayısal Belge ve İmge Dosyaları İçerisinde Kişisel Verilerin Tespiti, Sınıflandırılması ve Analizi.
Projemiz yapay zeka, derin öğrenme ve makine öğrenmesi tabanlı bir Ar-Ge projesidir. TÜBİTAK tarafından desteklenmiştir. Projemizde derin öğrenme ve makine öğrenmesi algoritmaları kullanılarak kimlik, ehliyet, pasaport, kredi kartı, kişi fotoğrafı vb. bilgileri içeren kişisel dokümanlar/fotoğraflar otomatik olarak tespit edilerek sınıflandırılması sağlanmıştır. Bu dokümanlarda bulunan T.C. kimlik numarası, ad-soyad, doğum tarihi, kan grubu, IBAN no, kredi kartı bilgileri, vb. bilgiler Optik Karakter Tanıma (OCR) yöntemleriyle tespit edilmiştir. Tespit edilen verilerle ilgili raporlar oluşturulmuş, kurumların tespit ettikleri kişisel verinin korunmasına yönelik önlem alması sağlanmıştır. E-posta, veri tabanı, dosya sistemleri geliştirilen KVKK aracıyla otomatik olarak taranarak kişisel verilerin tespit edilip otomatik olarak raporlanması sağlanmıştır.
Proje sonunda ortaya çıkan ürün KVKK Keşif adı ile ticarileşmiştir. Sunucu/istemci mimarisi üzerine kurgulanmıştır.
Sunucu uygulaması web uygulaması, arka plan servisi, analiz kuyruğu ve veri tabanı katmanı olmak üzere dört ana bileşen şeklinde kurgulanmıştır: Çalışma mantığı API uç noktaları üzerinden istemci uygulamalar tarafından iletilen içeriklerin FIFO mantığında çalışan bir kuyruğa eklenip kişisel veriler kapsamında çeşitli analiz süreçlerinden geçirilmesi ve sonuçların veri tabanında saklanması esasına dayanmaktadır.
Web (web) Bileşeni: Kullanıcı ara yüzlerini ve API uç noktalarını barındıran bir web uygulamasıdır. Python ekosistemindeki popüler web uygulama framework’lerinden olan “flask” framework’ü üzerinde geliştirilmiştir.
Arka plan servisi (worker) Bileşeni: Analiz servisine eş zamanlı olarak çok sayıda içerik iletilebileceğinden ve bu içeriklerin analiz edilmesinin belirli bir zaman alacak olmasından dolayı elde edilen içerikler sunucu dosya sistemine (ve ilgili meta data veri tabanına) yazıldıktan sonra içeriğin ID bilgisi kuyruğa yazılmakta ve bu kuyruktaki içerikler asenkron bir şekilde arka plan servisi tarafından çeşitli analiz işlemlerine tabi tutulmaktadır. Bu amaçla Python ekosisteminde, vakit alan arka plan işlemleri için tercih edilen popüler bir kütüphane olan “celery” kütüphanesi tercih edilmiştir.
Analiz Kuyruğu (rabbitmqhost) Bileşeni: İçeriklerin analiz edilmek üzere bekleyeceği ve FIFO mantığında çalışan bir kuyruk yapısı gereksinimi için “RabbitMQ” uygulaması tercih edilmiştir.
Veri tabanı (dbhost) Bileşeni: Uygulamaya ait her türlü kullanıcı verisinin saklanması için açık kaynaklı bir ilişkisel veri tabanı yönetim sistemi olan PostgreSQL veri tabanı tercih edilmiştir. Veri tabanı ile iletişime geçen “web” ve “worker” bileşenleri veri tabanı etkileşimi içine “sqlalchemy” isimli ORM kütüphanesini kullanmaktadır. Böylelikle ham sql sorguları ile işlem yapmaktan kaçınılarak programatik olarak sorgulama yapılmakta ve olası hatalar en aza indirilmektedir.
İstemci uygulaması ise hedef cihazlara kurulumu yapıldıktan sonra “agent” mantığında çalışan bir masaüstü uygulamasıdır.
Bu uygulama, sistem yetkilisi tarafından kurulum işlemi yapıldıktan sonra yapılacak olan tanımlama ve konfigürasyonların ardından manuel ya da otomatik olarak tercih edilen mecralardaki içeriklerin analiz sunucusuna iletilmesi görevini üstlenmektedir.
İstemci uygulaması iki ana bileşenden meydana gelmektedir: arka planda sürekli olarak çalışır durumda olan bir sistem servisi ve kullanıcı etkileşimi için tasarlanmış bir kullanıcı arayüzü uygulaması.
Arka plan uygulaması ilk kurulum sırasında sistem servisi olarak kaydedilmekte ve sürekli çalışır durumda olarak sistem servisleri arasında yerini almaktadır. Kullanıcı arayüzü uygulaması ile sistem servisi arasındaki iletişim “gRPC” protokolü üzerinden gerçekleşmektedir.
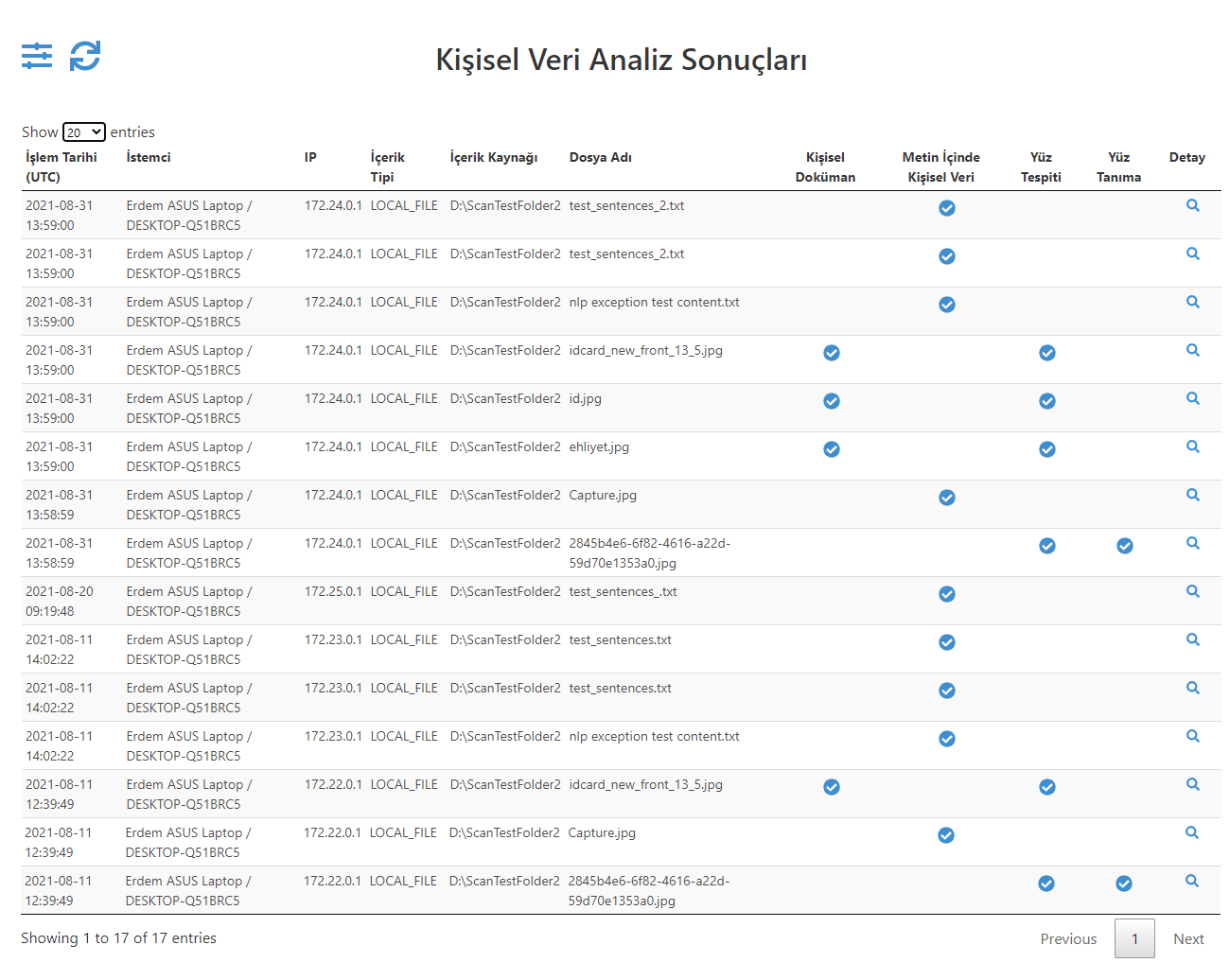
Şekil_1_Kişisel Veri Analiz Sonuçları Master Ekran
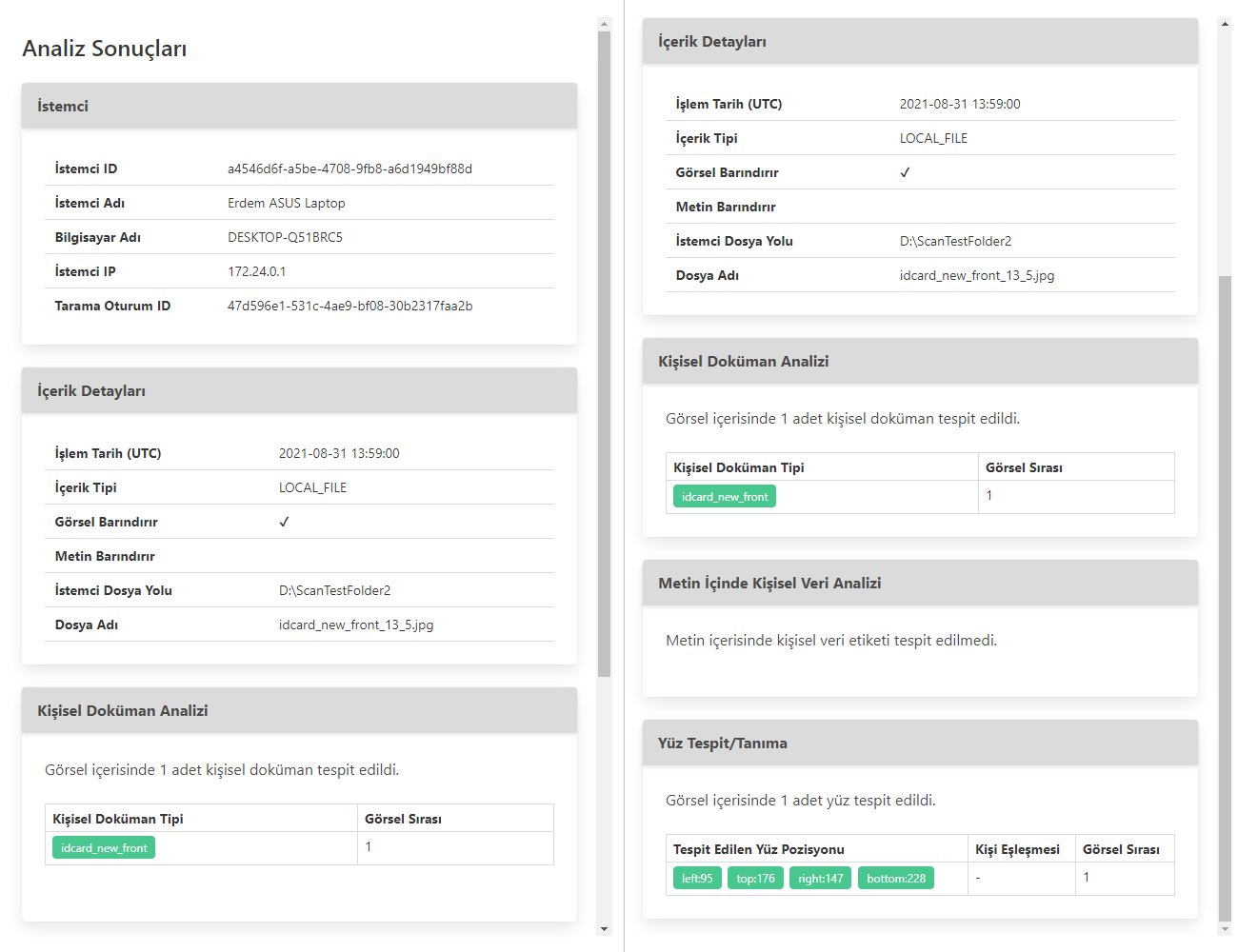
Şekil_2_Kişisel Veri Analiz Sonuçları Detay Ekran

