Detection, Classification and Analysis of Personal Data in Digital Document and Image Files.
Our project is an R&D project based on artificial intelligence, deep learning and machine learning. Supported by TUBITAK. In our project, deep learning and machine learning algorithms are used to create IDs, driver's licenses, passports, credit cards, personal photos, etc. Personal documents/photographs containing information were automatically detected and classified. T.R. ID number, name-surname, date of birth, blood type, IBAN no, credit card information, etc. contained in these documents. information was identified by Optical Character Recognition (OCR) methods. Reports on the detected data were created and institutions were enabled to take measures to protect the personal data they detected. E-mails, databases and file systems were automatically scanned with the developed PDPA tool, enabling personal data to be detected and reported automatically.
The product that emerged at the end of the project was commercialized under the name KVKK Discovery. It is built on server/client architecture.
The server application is built as four main components: web application, background service, analysis queue and database layer: The working logic is based on the fact that the content transmitted by client applications via API endpoints is added to a queue that works in FIFO logic, goes through various analysis processes within the scope of personal data and the results are stored in the database.
Web (web) Component:
A web application that hosts user interfaces and API endpoints. It was developed on the "flask" framework, one of the popular web application frameworks in the Python ecosystem.
Background service (worker) Component: Since a large number of content may be transmitted to the analysis service simultaneously and it will take a certain amount of time to analyze these contents, after the obtained contents are written to the server file system (and the related metadata database), the ID information of the content is written to the queue and the contents in this queue are subjected to various analysis processes by the background service asynchronously. For this purpose, the "celery" library, which is a popular library in the Python ecosystem for time-consuming background operations, was preferred.
Analysis Queue (rabbitmqhost) Component:
"RabbitMQ" application was preferred for the requirement of a queue structure that works in FIFO logic where the content will wait to be analyzed.
Database (dbhost) Component:
PostgreSQL database, an open source relational database management system, was preferred for storing all kinds of user data of the application. The "web" and "worker" components that communicate with the database use the ORM library named "sqlalchemy" to interact with the database. Thus, by avoiding processing with raw sql queries, queries are made programmatically and possible errors are minimized.
The client application is a desktop application that works in the "agent" logic after it is installed on the target devices.
This application undertakes the task of manually or automatically transmitting the content from the preferred channels to the analysis server after the definitions and configurations to be made after the installation process by the system authority.
The client application consists of two main components: a system service that runs continuously in the background and a user interface application designed for user interaction.
The background application is registered as a system service during the initial installation and is always running as a system service. The communication between the user interface application and the system service takes place via the "gRPC" protocol.
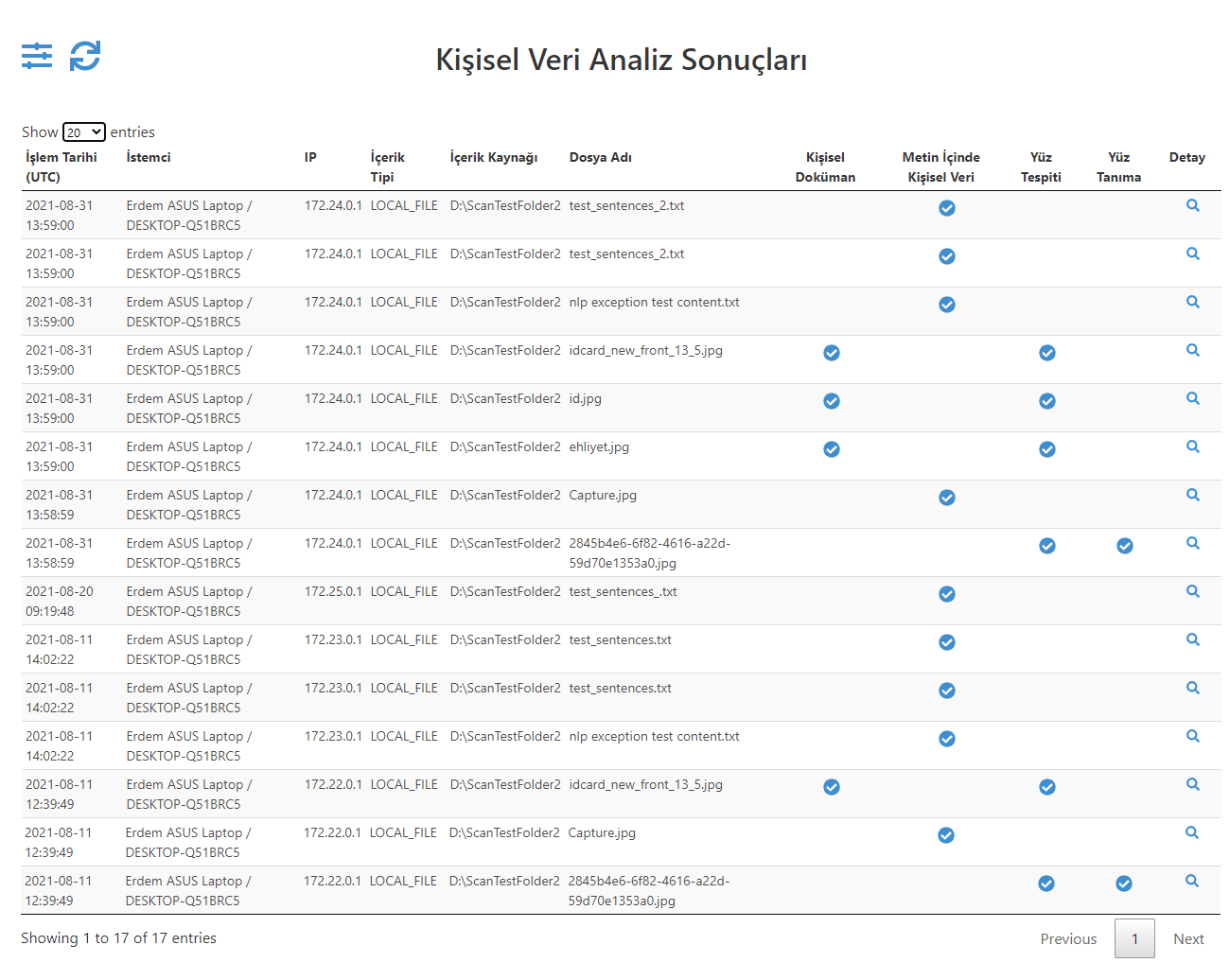
Figure_1_Personal Data Analysis Results Master Screen
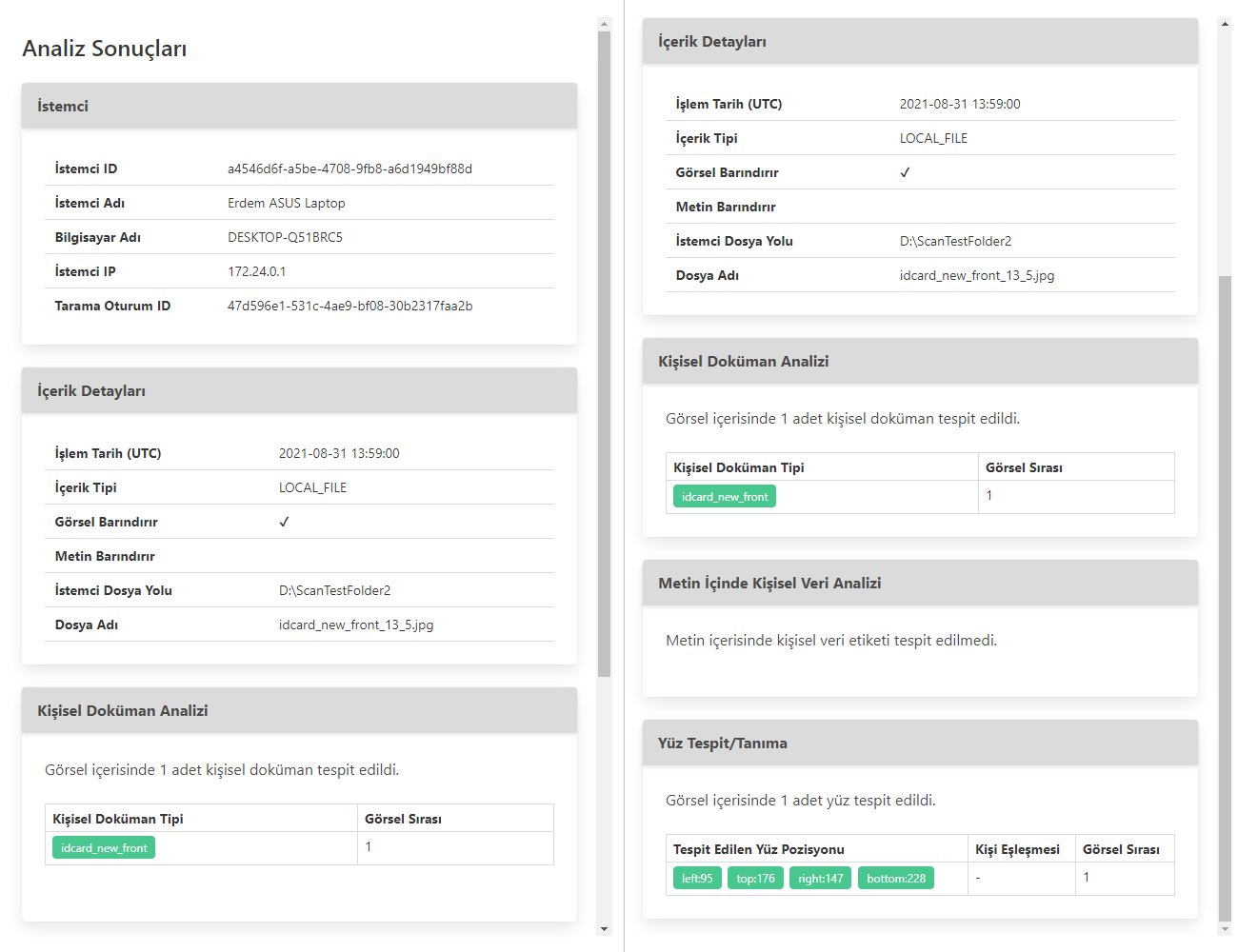
Figure_2_Personal Data Analysis Results Detail Screen

